⚙️ Tech Breakdown: Bullet Hell
I’m adding an Itano-style Missile Circus Attack right now, so let’s talk about the principles of a high-performance bullet-hell system.

Four thousand bullets ought to be enough for anyone.
Computers are fast. Your Nintendo Switch has four 1.02 GHz ARM Cortex-A57 CPU cores, each one 500x more powerful than the computer which sent us to the moon. So why is it slow to spawn a few thousand Bullet Objects?
It boils down to two issues: memory and memory (again).
These samples are for Unity, but the principles are engine-agnostic. For instance, I also applied them with the Unreal Game Engine in the development of Solar Ash. That translation is left as an exercise to the reader.
Memory Problem 1: Allocation and Object Pooling
Normally we add objects to the scene with Object.Instantiate(), which allocates managed memory for C# components as well as several handles to C++ native engine resources (meshes, transforms, etc). On removal, Object.Destroy() unregisters the resources, and releases its memory reference so that the garbage collector can come around later to return the RAM back to the system.
When this overhead is amortized over the lifetime of the object it doesn’t matter, but bullets are rapidly spawned and short lived, so we’re continuously creating them and tearing them down, which is a drag on performance.
An alternative is to pre-allocate a pool of hidden bullets. To spawn a bullet, we just grab an unused one, toggle its visibility, and put it in the right place. To remove, we simply hide it and put it back in the pool to be recycled.
I’ve implemented this several ways over the years, but here’s a pithy version that pleases me:
using UnityEngine;
public class PooledObject : MonoBehaviour
{
/*
For the prefab, next points at the head of the freelist.
For inactive instances, next points at the next inactive instance.
For active instances, next points back at the source prefab.
*/
[System.NonSerialized] PooledObject next;
public static T Create<T>(T prefab, Vector3 pos, Quaternion rot) where T : PooledObject
{
T result = null;
if (prefab.next != null)
{
/*
We have a free instance ready to recycle.
*/
result = (T) prefab.next;
prefab.next = result.next;
result.transform.SetPositionAndRotation(pos, rot);
}
else
{
/*
There are no free instances, lets allocate a new one.
*/
result = Instantiate<T>(prefab, pos, rot);
result.gameObject.hideFlags = HideFlags.HideInHierarchy;
}
result.next = prefab;
result.gameObject.SetActive(true);
return result;
}
public void Release()
{
if (next == null)
{
/*
This instance wasn't made with Create(), so let's just destroy it.
*/
Destroy(gameObject);
}
else
{
/*
Retrieve the prefab we were cloned from and add ourselves to its
free list.
*/
var prefab = next;
gameObject.SetActive(false);
next = prefab.next;
prefab.next = this;
}
}
}
You may be asking: I said there’d be a pool. Where is it? Shouldn’t there be a List<T> or something somewhere?
It’s actually all there in the next reference. The pool is a Linked List where each instance points at the next item in a list, like a chain. A picture is worth 1,000 words:
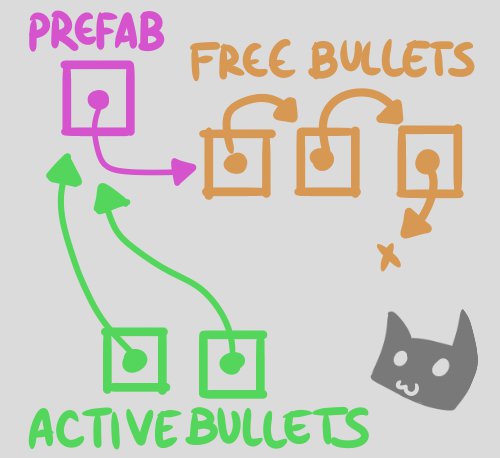
The prefab points at the first free bullet, and each free bullet points to the next free bullet. Active bullets point back at the prefab so they know where to go when they’re recycled.
All from one field.
With this method we can create and release bullets with a just few cheap assignments. Once the pool size stabilizes we no longer have to allocate or deallocate any memory for as long as the scene continues to run. As a nice bonus, we naturally get separate freelists for every type of prefab that’s pooled.
Challenge question: can you implement a function to free-up unused resourced by Destroy()ing the freelist?
Memory Problem 2: Context-Switching and Data-Oriented Design
Pooling eliminates the cost of creating and destroying bullets, but our profiler still shows a pretty siginifcant cost Update()ing them. In particular are two slow operations:
UnityEngine.Physics.Raycastchecking for impact collisionsUnityEngine.Transform.position=updating the scene position
If you dig even deeper (e.g. using a hardware profiler like VTune), you’ll see that both of these methods spend most of their time fetching data. This is called a pipeline stall.
I won’t go too deep into this topic, since whole books have been written about it, but basically while the CPU is very fast, memory is very slow. If we can’t keep the CPU fed with data, it will spend most it’s time waiting around.
What follows is a simplified explanation that glosses over a lot, but is good-enough-for-game-programmers.
Memory is divided into two parts: a large pool of DRAM which is attached to the CPU over a bus, and a small cache of fast SRAM which is on the CPU die. When the CPU attempts to accesses uncached memory it’s called cache miss, which triggers a system interrupt to copy the data from main memory to the cache. Since the cache is limited, stale memory in the cache is retired-back to main memory to make room. Cache hits are fast, but misses are slow – dozens or even hundreds of cycles.
E.g. you could calculate several trig functions or multiply several matrices together during one single cache-miss.
During the bullet update, four distinct chunks of memory are accessed:
- The executable machine code, or instructions, which are placed in a dedicated ICACHE.
- The gameplay script data, stored in C# objects.
- The PhysX spatial collision data, stored on the C++ heap.
- The transform hierarchy data, stored natively in the engine.
ICACHE misses happen when code is interleaved. So for instance, code like this:
Foo(x);
Bar(x);
Baz(x);
Foo(y);
Bar(y);
Baz(y);
Foo(z);
Bar(z);
Baz(z);
… won’t be expected to perform as well (subject to complexity and compiler inlining) as sorted code like this:
Foo(x);
Foo(y);
Foo(z);
Bar(x);
Bar(y);
Bar(z);
Baz(x);
Baz(y);
Baz(z);
… because it’s busting the cache and reloading instructions on every other line, as opposed to reusing code while it’s still hot.
For bullets, this suggests first changing from every bullet having it’s own Update() interleaved with other scripts to a single BulletSystem which updates them all at once, e.g.
class BulletSystem
{
Bullet[] bullets;
int bulletCount;
void Update()
{
float dt = Time.deltaTime;
for (int it = 0; it < bulletCount; ++it)
{
var distance = bullets[it].speed * dt;
if (Physics.Raycast(bullets[it].pos, bullets[it].dir, out var hit, dist))
{
// hit something
bullet.Release();
HandleBulletImpact(hit);
}
else
{
// advancing
bullets[it].pos += distance * bullets[it].dir;
bullets[it].transform.position = bullets[it].pos;
}
}
}
}
Now all the position-calculations are performed together and the instructions only need to be fetched once. Furthermore, if bullets is an array of C# structs, as opposed to classes, then the state data will inline without indirection, further minimizing the cache miss rate (since nearby data is batched in pages and lines that are cached in chunks).
Depending on your access pattern, you can go even further – refactoring the bullets array into several parallel arrays for different fields like position and velocity. This is called the “Array of Structures to Structure of Arrays” transformation. Many programmers are so enamored of this technique that it can become something of a cargo cult.
But we still have the calls into Physics.Raycast and Transform.position= busting the cache accessing a bunch of data that’s not local to the UpdateBullets() script. Here’s an illustration:
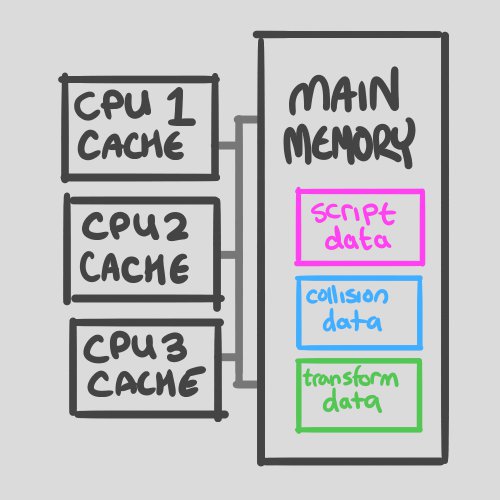
Fig.1 All the data in main memory, attached to multiple CPU cores via the system bus.
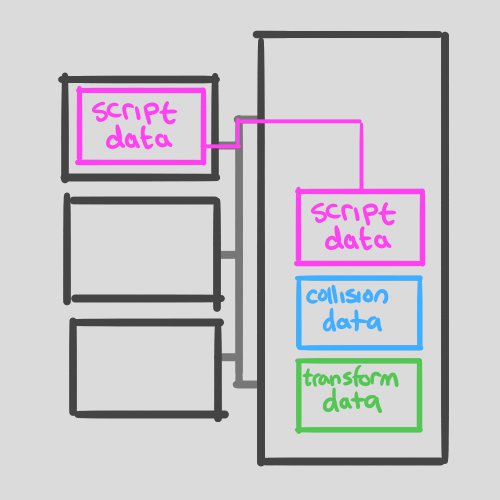
Fig.2 BulletSystem.Update() runs and script data is cached.
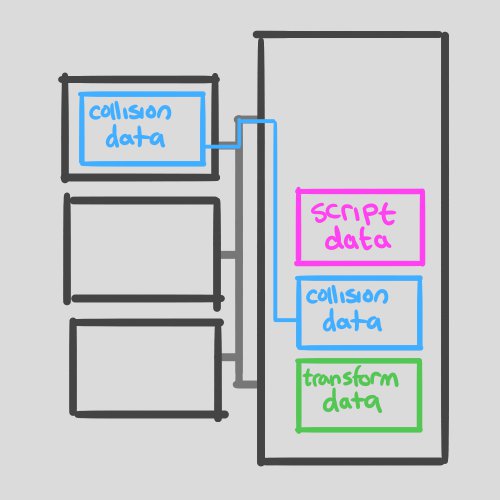
Fig.3 Physics.Raycast busts the cache.
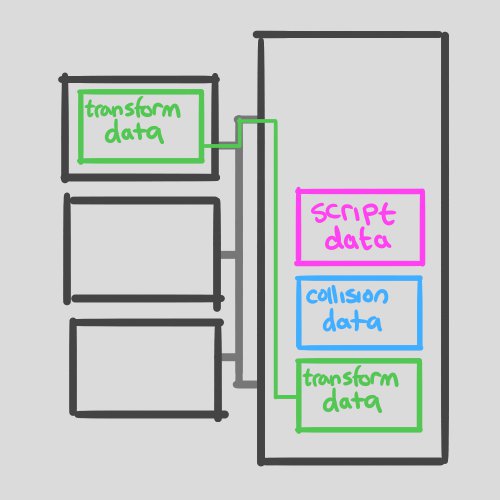
Fig.4 Transform.position= busts the cache again.
Now when the for-loop iterates we have to reload the script data and do everything again, for every bullet – thousands of times. You can see how cache misses pile up – we keep context switching between different data structures.
For a long time this was an intractable problem with Unity, but in 2017 the Job System was introduced to address batch-processing like this. I’ve suggested how this works in my illustration – we’re going to “schedule” work on other CPUs in Update(), and then gather their results in LateUpdate(). Each CPU will keep the different types of data hot in their respective caches, minimizing the cache miss rate.
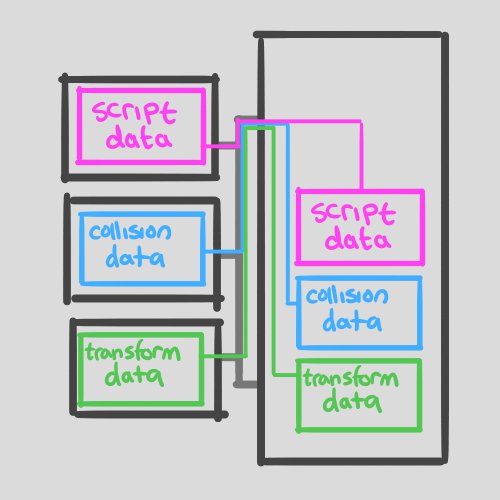
Fig.5 By dedicating different threads to different jobs, we keep more relevant data hot in the cache more often.
Unity provides RaycastCommand for physics query jobs and IJobParallelForTransform for scene transformations. Unfortunately, the code for this is too complex for a code snippet in a blog, but here’s a abridged version to give you a sense of the implementation:
struct BulletTransformJob : IJobParallelForTransform
{
[ReadOnly]
public NativeArray<Vector3> positions;
public void Execute(int index, TransformAccess transform) {
transform.localPosition = positions[index];
}
};
class BulletSystem
{
const int CAPACITY = 4096;
Bullet[] bullets;
int bulletCount = 0;
TransformAccessArray transforms;
NativeArray<Vector3> positionsToWrite;
JobHandle txJob;
NativeArray<RaycastCommand> commands;
NativeArray<RaycastHit> results;
JobHandle physJob;
void Awake()
{
/*
Allocate all the buffer memory we'll need up-front
*/
inst = new Bullet[CAPACITY];
transforms = new TransformAccessArray(CAPACITY);
results = new NativeArray<RaycastHit>(CAPACITY, Allocator.Persistent, NativeArrayOptions.UninitializedMemory);
commands = new NativeArray<RaycastCommand>(CAPACITY, Allocator.Persistent, NativeArrayOptions.UninitializedMemory);
positionsToWrite = new NativeArray<Vector3>(CAPACITY, Allocator.Persistent, NativeArrayOptions.UninitializedMemory);
}
void Update()
{
if(bulletCount == 0)
{
return;
}
float dt = Time.deltaTime;
/*
Build job input buffers.
*/
for (int it=0; it<bulletCount; ++it)
{
var bullet = bullets[it];
positionsToWrite[it] = bullet.pos + ( dt * bullet.speed ) * bullet.dir;
commands[it] = new RaycastCommand(bullet.pos, bullet.dir, bullet.speed * dt);
}
/*
Schedule a batch transform update.
*/
BulletTransformJob job;
job.positions = positionsToWrite;
txJob = job.Schedule(transforms);
/*
Schedule a batch of physics queries.
*/
physJob = RaycastCommand.ScheduleBatch(commands.GetSubArray(0, bulletCount), results.GetSubArray(0, bulletCount), 1);
}
void LateUpdate()
{
if(bulletCount == 0)
{
return;
}
float dt = Time.deltaTime;
/*
Wait for both jobs to finish, if they're still going.
*/
txJob.Complete();
physJob.Complete();
/*
Handle bullet impacts, swapping with the end of the array to remove
*/
for(int it=0; it<bulletCount;)
{
var bullet = bullets[it];
var hit = results[it];
if(hit.collider == null)
{
bullet.pos += (dt * bullet.speed) * bullet.dir;
++it;
continue;
}
bullet.Release();
HandleHit(hit);
--bulletCount;
transforms.RemoveAtSwapBack(it);
if(it < bulletCount)
{
bullets[it] = bullets[bulletCount];
results[it] = results[bulletCount];
}
bullets[bulletCount] = null;
}
}
void OnDestroy()
{
/*
Clean up after ourselves.
*/
transforms.Dispose();
results.Dispose();
commands.Dispose();
positionsToWrite.Dispose();
}
}
Just a quick look at the profiler in my stress-testing scene, and we’re comfortably above 100FPS. Most of the script time is actually spent on a quick-and-dirty prototype script that has nothing to do with bullets. 🤡
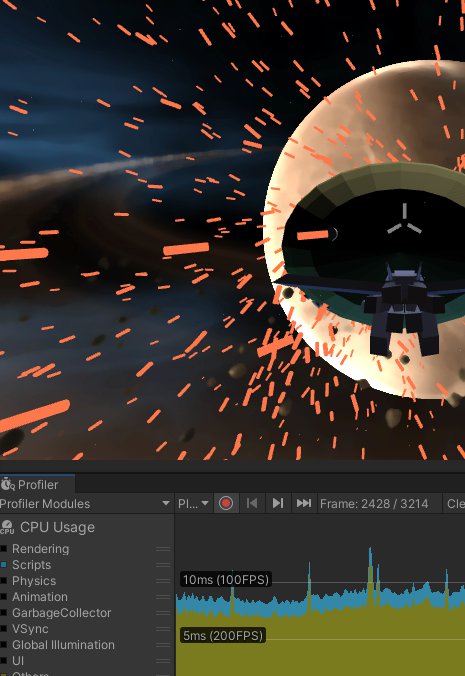
This isn’t even a build - this is in the editor, which is slow anyway.
I could push this further by simplifying the bullet objects themselves, or perhaps even rendering them with GPU Instancing as opposed to MeshRenderers, but for this early phase of development I’m happy knowing I don’t have any unsolvable problems which can come back to bite me later.